📄 Preparing Data & Generating Embeddings
In our previous post we explored how to access and interact with Large Language Models (LLMs) using providers like Amazon Bedrock. Now, we move on to the next step in building a RAG chatbot: preparing your data and generating vector embeddings.
🧠 Why Data Preparation Matters
LLMs are powerful — trained on vast internet-scale datasets, they excel at understanding and generating human language. However, they lack context about your specific domain or internal data. That’s where RAG comes in.
To enable an LLM to reason over your data, you must first:
- Format it properly
- Convert it into machine-understandable vectors
- Store and retrieve it efficiently
This step — preparing your data pipeline — is crucial for any RAG-based application.
🏞 Structured vs Unstructured Data
Today’s data landscape is evolving. Traditional data warehouses are giving way to data lakes and lakehouses, handling both structured (CSV, SQL) and unstructured (PDFs, docs, text) content equally.
In this series, we’ll focus on unstructured data — PDFs, text files, etc. — and use LLMs to extract insights from them conversationally.
🔍 Use Case: Think of a student prepping for exams using an LLM that answers questions from a textbook. That’s RAG in action.
🖼 RAG Architecture with Data Pipeline
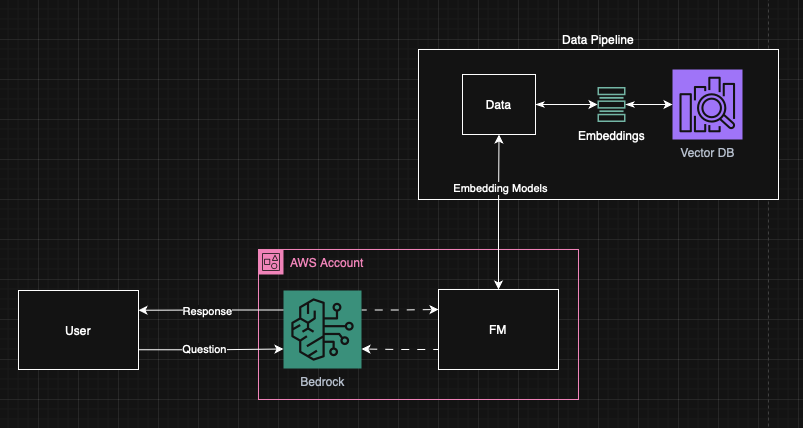 Fig 1: RAG Architecture with Data Pipeline
Fig 1: RAG Architecture with Data Pipeline
📊 Data Processing Flow:
- Document Ingestion → PDF, Word, Text files
- Text Extraction → Parse and clean content
- Chunking Strategy → Split into manageable segments
- Embedding Generation → Convert text to vectors
- Vector Storage → Store in vector database
- Retrieval & Generation → Query matching and response generation
🔧 Understanding Embeddings
LLMs don’t understand raw text. We must convert our unstructured data into embeddings — numerical representations that encode semantic meaning.
Embeddings allow LLMs to “reason” over text by comparing the vector similarity between user queries and stored knowledge.
🏗 Providers of Embedding Models
Some popular embedding providers include:
- Amazon Titan Embeddings
- OpenAI Embeddings
- Cohere
- Google Vertex AI
- HuggingFace models
For this tutorial, we'll use Amazon Titan via Bedrock.
🔗 Amazon Titan Embeddings on Bedrock
🧱 Building the Data Pipeline
Here’s a high-level overview:
- Access raw document data
- Split documents into manageable chunks
- Convert chunks into embeddings
- Store embeddings in a vector database
- Search embeddings by query
- Feed relevant chunks into an LLM for a final answer
🛠 Tools Used
- LangChain: For document splitting and LLM abstraction
- FAISS: In-memory vector database for fast retrieval
- Bedrock: AWS Bedrock, serverless service for accessing different FMs
!!! note "Using LangChain for Rapid Development"
For this demo, we’ll be using LangChain, an open-source framework for building LLM-based applications. LangChain simplifies the complexity of accessing LLMs by providing convenient abstractions and wrappers, allowing developers to build powerful applications faster and reduce time to market.
✂️ Step 1: Splitting Text into Chunks
def create_chunks(self, documents: List,
chunk_size: int = 1000,
chunk_overlap: int = 200) -> List:
"""
Split documents into chunks with error handling
Args:
documents: List of documents to chunk
chunk_size: Size of each chunk
chunk_overlap: Overlap between chunks
Returns:
List of document chunks
"""
try:
if not documents:
logger.warning("No documents provided for chunking")
return []
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_documents(documents)
logger.info(f"Split {len(documents)} documents into {len(chunks)} chunks")
return chunks
except Exception as e:
logger.error(f"Error creating chunks: {e}")
return []
✅ Recommended:
chunk_size: 500–1000 characterschunk_overlap: 10–20% of chunk size
This ensures context is preserved across chunks.
🔢 Step 2: Generating Embeddings
def _get_bedrock_embeddings(self) -> Optional[BedrockEmbeddings]:
"""Initialize and return Bedrock embeddings with error handling"""
try:
# Get AWS credentials
aws_access_key_id = os.getenv("AWS_ACCESS_KEY_ID")
aws_secret_access_key = os.getenv("AWS_SECRET_ACCESS_KEY")
embeddings_kwargs = {
"model_id": self.embedding_model_id,
"region_name": self.region
}
# Add credentials if available
if aws_access_key_id and aws_secret_access_key:
embeddings_kwargs.update({
"credentials_profile_name": None # Use explicit credentials
})
embeddings = BedrockEmbeddings(**embeddings_kwargs)
logger.info(f"Initialized Bedrock embeddings with model: {self.embedding_model_id}")
return embeddings
except Exception as e:
logger.error(f"Failed to initialize Bedrock embeddings: {e}")
return None
🗃 Step 3: Storing in Vector DB
# Create vector store
logger.info("Creating FAISS vector store...")
vector_store = FAISS.from_documents(
documents=chunks,
embedding=self.embeddings
)
# Save vector store
os.makedirs(os.path.dirname(vector_db_path) if os.path.dirname(vector_db_path) else '.', exist_ok=True)
vector_store.save_local(vector_db_path)
logger.info(f"FAISS vector database created and saved to {vector_db_path}")
🧠 Other vector DBs to explore:
- ChromaDB
- Weaviate
- Pinecone
- Amazon OpenSearch
🔍 Step 4: Querying the Vector DB
# Load vector database if not provided
if vector_db is None:
vector_db = self.load_vector_db(vector_db_path)
if vector_db is None:
return "Failed to load vector database. Please ensure the database exists and is accessible."
# Search for relevant documents
logger.info(f"Searching for relevant documents for question: {question[:100]}...")
docs = vector_db.similarity_search(question, k=k)
✅ Our Data is Now Searchable!
Now that our embeddings are stored and indexed, we can query them — and pass the results to an LLM to generate a contextual answer.
🧪 Example: Querying Documents
To demonstrate the pipeline, I’ve selected Google’s prompt engineering whitepaper as the input document — a detailed resource outlining advanced prompting strategies.
Document Source: Google’s Prompt Engineering Whitepaper (PDF)
# Prepare context
context = "\n\n".join([doc.page_content for doc in docs])
# Create prompt
prompt = f"""You are a helpful assistant that answers questions based on the provided context from PDF documents.
Context:
{context}
Question: {question}
Instructions:
- Answer the question based only on the provided context
- If the context doesn't contain enough information, say "I don't have enough information to answer this question based on the provided documents"
- Be concise but comprehensive in your answer
- Cite relevant parts of the context when possible
Answer:"""
# Get answer from Claude
logger.info("Getting answer from Bedrock Claude...")
answer = self.call_bedrock_claude(prompt)
return answer
📸 Output
Prompt:
"What is a prompt?"
Output:
Based on the provided context, a prompt is an input given to a Large Language Model (LLM) to generate a response or prediction. When you write a prompt, you are trying to guide the LLM to predict the right sequence of tokens. The context specifically states that "in the context of natural language processing and LLMs, a prompt is an input provided to the model to generate a response or prediction.
Prompts can take different forms, including:
- Zero-shot prompts (which provide just a description of a task without examples)
- Role prompts (where the AI is assigned a specific role)
- Multimodal prompts (which can combine text, images, audio, code, or other formats)
The effectiveness of a prompt often requires tinkering and optimization of factors like length, writing style, and structure in relation to the task at hand."
🎯 Example RAG Query Response
Query: "What are the key benefits of using vector embeddings in RAG applications?"
Response: The RAG application successfully processes the query through the vector database, retrieves relevant context, and generates a comprehensive response highlighting the advantages of vector embeddings in semantic search and retrieval accuracy.
You can access the full code on GitHub here.
📌 Summary
In this post, we covered:
- Why unstructured data matters in RAG
- What embeddings are and how they power LLM search
- How to split, embed, and store your documents
- How to query the knowledge base using FAISS
- Explored retrieval and generation using your vector database
- LLM to answer user queries interactively
🔮 Next Up
Next, we’ll explore prompt engineering techniques.
Subscribe or follow to continue your RAG journey 🚀