🧠 Accessing LLMs
Welcome to RAG to Riches, a series where we'll explore the key components involved in building a RAG (Retrieval-Augmented Generation) chatbot. Whether you're new to the space or looking to solidify your understanding, this series will walk through each building block — with hands-on code, real-world use cases, and lessons learned.
🤖 What is RAG?
RAG, or Retrieval-Augmented Generation, is a method where we enhance Large Language Models (LLMs) by supplying them with external, domain-specific knowledge. Instead of training the model from scratch or fine-tuning it (which can be expensive and rigid), RAG pipelines inject relevant contextual data into the model at runtime — giving it the ability to answer questions with up-to-date, accurate, and business-specific information.
RAG enables LLMs to provide accurate, up-to-date responses by combining their reasoning capabilities with external knowledge sources, making them perfect for business applications.
🧠 Traditional ML vs LLMs
Traditional machine learning models are typically trained for narrow tasks — like classification, regression, or entity recognition. They're effective, but often require custom training and don't generalize well outside their training domain.
LLMs, in contrast, are trained on vast corpora of internet-scale data and are capable of handling multiple tasks with little or no task-specific training. With techniques like RAG, we can guide these general-purpose models to perform focused tasks in a business context by injecting relevant knowledge into the prompt.
💡 Why RAG?
RAG is a practical, scalable way to:
- Introduce LLMs into business applications without extensive retraining
- Deliver consistent and accurate answers from a centralized knowledge base
- Build intelligent, context-aware conversational bots or assistants
- Internal Documentation Chatbots - Answer questions from company knowledge bases
- Customer Service Bots - Respond using product-specific information
- Business Intelligence Assistants - Pull insights from reports and data stores
🧱 Components of a RAG Pipeline
To build a fully functional RAG chatbot, the typical steps are:
- Identify and prepare business-specific data
- Generate embeddings from the data
- Store embeddings in a vector database
- Access an LLM to serve as the reasoning engine
- Retrieve relevant context and generate responses
We'll cover each of these steps in detail throughout this series. This post focuses specifically on step 4 - accessing LLMs.
🔍 Focus of This Post: Accessing LLMs
Before we dive into embeddings or vector databases, we need to know how to access a foundational model — the heart of the RAG chatbot. Today, there are several ways to do that:
🔌 Major Providers
- Amazon Bedrock – Offers access to multiple models (Anthropic Claude, Meta Llama, Mistral, Cohere, etc.) through a single unified API
- OpenAI – Creator of ChatGPT and GPT-4, provides models like
gpt-3.5-turboandgpt-4via API - Anthropic – Developer of the Claude series of models
- Google Cloud – Offers access to Gemini and PaLM models through Vertex AI
- Azure OpenAI – Microsoft's hosted OpenAI models on Azure infrastructure
Each of these services allows you to use powerful models through simple API calls — enabling integration into your app, chatbot, or internal tool.
🧪 Accessing Model via AWS Bedrock
For demo purposes, we'll use Amazon Bedrock to access a foundational model and ask a few questions. Bedrock makes it easy to experiment with different models while abstracting away the infrastructure complexity.
We'll write a simple Python script that:
- Connects to Bedrock using the AWS SDK (
boto3) - Selects a model (e.g., Claude v2 or Meta Llama 3)
- Sends a prompt and receives a response
✅ Prerequisites
- AWS account with Bedrock access enabled
- IAM role or user with permissions to invoke models
- Python 3.9+ and
boto3installed
🛠 Environment Setup
To follow along with the demo, let's set up a basic Python environment.
🔧 Create a Virtual Environment
python3 -m venv rag-env
source rag-env/bin/activate
# On Windows use: rag-env\\Scripts\\activate
# Install libraries
pip install boto3 botocore
🔐 Setting Up Environment Variables and Parameters
To securely access Amazon Bedrock and keep your code clean, it's good practice to use environment variables for configuration.
🧾 Required AWS Environment Variables
You'll need to set the following in your terminal or through a .env file:
export AWS_ACCESS_KEY_ID=your-access-key-id
export AWS_SECRET_ACCESS_KEY=your-secret-access-key
export AWS_DEFAULT_REGION=your-region # e.g., us-east-1
Never hardcode credentials in your source code. Always use environment variables, AWS IAM roles, or AWS credential files for authentication.
📋 RAG Architecture Overview
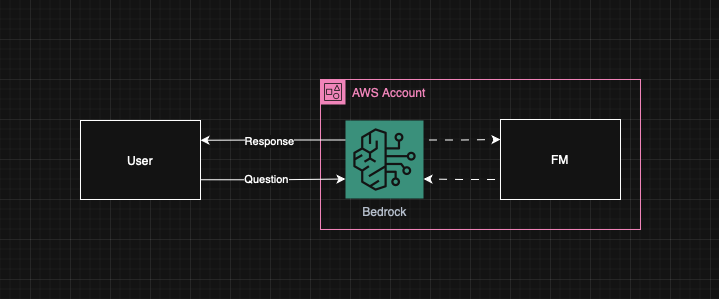
Figure 1: High-level architecture of accessing FM using AWS Bedrock.
The high-level architecture for accessing Foundation Models using AWS Bedrock involves:
- Client Application → API Gateway → Lambda Functions
- AWS Bedrock → Foundation Models (Claude, Llama, etc.)
- Vector Database → Embeddings storage and retrieval
- Data Pipeline → Document processing and embedding generation
🧾 Code Implementation
Here are two approaches to access AWS Bedrock models:
Direct AWS SDK Approach
"""
Calls the AWS Bedrock Claude Sonnet 4 model
with the given prompt.
Optionally accepts AWS access key and secret.
Returns the model's response as a string.
"""
import boto3
import json
# Initialize the Bedrock runtime client
bedrock = boto3.client(
"bedrock-runtime",
region_name=region,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key
)
# Example prompt to the model
prompt = "What is Retrieval-Augmented Generation (RAG) in AI?"
# Invoke the model
model_id = "us.anthropic.claude-sonnet-4-20250514-v1:0"
native_request = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"temperature": 0.5,
"messages": [
{
"role": "user",
"content": [{"type": "text", "text": prompt}],
}
],
}
request = json.dumps(native_request)
response = bedrock.invoke_model(modelId=model_id, body=request)
model_response = json.loads(response["body"].read())
response_text = model_response["content"][0]["text"]
# Print the response
print(response_text)
LangChain Approach
"""
Calls the AWS Bedrock Claude Sonnet 4 model using LangChain.
Optionally accepts AWS access key and secret.
Returns the model's response as a string.
"""
from langchain_aws import ChatBedrock
from langchain_core.messages import HumanMessage
try:
model_id = "us.anthropic.claude-sonnet-4-20250514-v1:0"
chat = ChatBedrock(
model_id=model_id,
region_name=region,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key
)
response = chat([HumanMessage(content=prompt)])
return response.content
except Exception as e:
print(f"Error calling Claude Sonnet 4 (LangChain): {e}")
return None
You can access the full code on GitHub here.
📸 Expected Output
Prompt:
What is Retrieval-Augmented Generation (RAG) in AI?
Response:
Retrieval-Augmented Generation (RAG) is a technique that combines the capabilities of large language models (LLMs) with external knowledge sources. Instead of relying solely on what the model was trained on, RAG retrieves relevant information from a vector database and incorporates it into the model's response generation process. This allows for more accurate, up-to-date, and contextually relevant outputs, especially in domain-specific applications.
Please make sure you have access to the models of your interest in your account and follow the documentation to format the request properly to avoid issues like:
botocore.errorfactory.AccessDeniedException: An error occurred (AccessDeniedException) when calling the InvokeModel operation: You don't have access to the model with the specified model ID.
botocore.errorfactory.ValidationException: An error occurred (ValidationException) when calling the InvokeModel operation: Malformed input request, please reformat your input and try again.
🔗 References
In this post, we explored how to access large language models through services like Amazon Bedrock and OpenAI.
Amazon Bedrock supports multiple foundational models like Claude and Titan, which you can explore in detail here. To start using these services, you'll also need to configure your AWS credentials.
📋 Summary
In this post, we covered:
- What RAG is and why it's useful for business applications
- How LLMs differ from traditional machine learning models
- The key steps involved in building a RAG system
- How to access a foundational model using Amazon Bedrock
- Practical code examples using both direct AWS SDK and LangChain approaches
Accessing an LLM is the first foundational step in building a RAG pipeline. Once you've connected to a model, you're ready to start injecting knowledge — and that's exactly what we'll explore next.
🔮 Coming Up Next…
In Part 2, we'll cover how to prepare your data and generate embeddings — turning your documents into searchable vectors that LLMs can understand and reason about.
Part 2: Data Setup and Embeddings - Learn how to prepare and vectorize your data for RAG applications.
Stay tuned and follow along as we go from RAG… to riches.